

Coursera Deep Learning専門講座の受講メモ (コース5 - Sequence Models - Week 1)

この記事のまとめ:
- CourseraのDeep Learning専門講座のコース5: Sequence ModelsのWeek 1の受講メモとして、要点とよくわからなかったところを補完のために調べたことなどを備忘録としてまとめています。
- Week 1ではシーケンスモデルの基本的な入出力表現やネットワーク構成について学びます。
コース5:Sequence Modelsについて
このコースでは、再帰型ニューラルネットワーク(Recurrent Neural Networks)の基本的なネットワーク構成と、応用例として自然言語処理におけるWord Embeddingや感情分類、機械翻訳、音声認識について学びます。
3週間の内容は次の通りです。
- Week 1: シーケンスモデルの基本的な入出力表現やネットワーク構成
- Week 2: 自然言語処理におけるWord Embeddingと感情分類
- Week 3: Sequence to sequenceモデルとして、機械翻訳、音声認識の応用
Week 1の概要
このコースのWeek 1では、次のことについて学びます。
- シーケンスモデルの基本的な入出力表現
- シーケンスモデルを扱うニューラルネットワークであるRNNの種類
- 基本的なRNNの数式表現
- RNNにおける勾配損失問題に対処としてのGRUとLSTM
- Bidirectional RNNとDeep RNNの概要
シーケンスモデルの適用例
シーケンスモデルは入力データとして時系列データを扱い、応用例として、スピーチ認識、音楽生成、感情分析、DNA分析、機械翻訳、ビデオ行動認識、キーワード抽出などがあります。
文章認識の入出力表現
シーケンスモデルの入出力表現として、固有名詞抽出を例に見ていきます。
入力 は単語ごとにわけ、それぞれ時系列のインデックスを添え字として山括弧を使って表現します。値については単語辞書のインデックスに対応したOne-hotベクトルで表現します。また、出力 においては、固有名詞であれば 、そうでなければ というように表現します。
| Harry | Potter | and | Hermione | Granger | invented | a | new | spell. | |
|---|---|---|---|---|---|---|---|---|---|
なお、ここでインデックス変数として を用い、 を入出力の最後のインデックスを示します。
これまで学んできた標準的なニューラルネットワークでこの問題を扱えない理由として次のような課題があります。
- インプットとアウトプットが例ごとに異なる長さになる可能性がある
- 異なる位置で出てきた特徴に対して適用できない
こういった理由でシーケンスモデルのニューラルネットワークを扱います。
再帰型ニューラルネットワーク (Recurrent Neural Networks: RNN)
シーケンスモデルを扱うニューラルネットワークとして再帰型ニューラルネットワークがあります。再帰型ニューラルネットワークの基本的な表現についてみていきます。
順伝播
再帰型ニューラルネットワークでの各隠れ層は、時刻 における入力 と時刻 の隠れ層の活性化関数 を入力として、出力 を得る構成となっています。その時に用いる重みが時刻ごとに異なる重みを使うわけでなく、すべての時刻において同じ重みを使います。

式で表すと次のようになります。
、、、、はそれぞれパラメーターで、、 は隠れ層間と出力用の活性化関数です。RNNでは にはtanh関数が使われることが多いです。 には二項分類にはシグモイド関数、他分類にはソフトマックス関数などが使われます。
計算の単純化のために、上記 の式は次のようにまとめることができます。
このとき、 と は次の通りです。
このように、ネットワーク状態が再帰的な構造となっており、過去の状態に依存する点がこれまで行ってきたニューラルネットワークとは異なります。
逆伝播
RNNの逆伝播の標準的な方法であるBPTT (Backpropagation through time)法を見ていきます。BPTT法は、簡単に言うと時刻 から まで一つ一つ展開していくとこれまで行ってきた逆伝播の方法がそのまま適用できるというものです。

まずは損失関数を定義します。出力は各時刻それぞれにありますので二項分類を例にすると次にようになります。
あとは、各パラメーターにおける損失関数の勾配を求めるために、損失関数を各パラメーターで微分します。
ここで、BPTT法と従来のニューラルネットワークの逆伝播と異なる点は、 が を含んでいることです。つまり、 を微分する際、次のようになります。
あとは従来通りに逆伝播の計算をすればよいです。
このように勾配には過去のすべての情報が含まれるという点が従来のニューラルネットワークの逆伝播と異なるということを理解しておく必要があります。
RNNの入出力の種類
これまで、入出力の長さが同じRNNを見てきましたが、RNNにはさまざまなタイプの入出力があります。
- One to many

- Many to one

- Many to many

- Many to many

RNNを使用した言語モデルの基本
言語モデルとは、自然言語処理において最も基本的で重要なタスクの一つで、Wikipediaでは次のように説明されています。
言語モデルとは,単語列に対する確率分布である.長さmの単語列が与えられたとき,単語列全体に対しての確率 を与える. 言語モデルを用いると異なるフレーズに対して相対的な尤度を求めることができるため,自然言語処理の分野で広く使われている. 言語モデルは音声認識,機械翻訳,品詞推定,構文解析,手書き文字認識,情報検索などに利用されている.
ここではRNNを用いて言語モデルを構築します。まずは、対象とする言語の大量のコーパスが必要になります。また、確率を求めるために、辞書もあらかじめ用意しておく必要があります。辞書の中には文章の終わりを示す"<EOS>"(End of Sentence)と、辞書に含まれていない単語を示す"<UNK>"(Unknown)を含める必要があります。
次のようなRNNにおいて文章を訓練することで言語モデルを作ることができます。

RNNは次で表す式に基づいて訓練しますが、ソフトマックス関数は までの文章を与えられたときに、辞書の中の単語からそれぞれの確率を予測することを意味します。
なお、言語モデルとして文字レベルの言語モデルも作ることはできますが、次のようなPro/Conがあります。
| Pro | Con |
|---|---|
| unknownの文字が来ても対応できる | 訓練するには計算コストが大きすぎる |
Sampling novel sequences
学習済みの言語モデルを用いて新しい文章を作ることができます。
ランダムに1語目を選び、以後は前の を入力として、RNNが導く分布からランダムに言葉を抽出し、出力 していくと、文章を生成してくれます。
RNNにおける勾配損失問題
ディープニューラルネットワークでは浅い層の情報を深い層に影響を与えることは難しいです。これは以前にも触れた勾配損失問題によるものです。
その対策として、GRUやLSTMがあります。
Gated Recurrent Unit (GRU)
GRUでは隠れ層の中に過去の状態を覚えておくためのパラメーターとして memory cell があります。また、 を更新するかどうかのゲートである update gate があり、この値は常に1か0に近い値を示すように働きます。この二つの働きによって過去の状態を出力に反映させるかどうかの働きをします。最後に の次の候補を計算するのに がどれほど関連性があるかを示す relevance gate があります。

上図では単純化のためにrelevance gateは省略しています。
式で表すと次のようになります。
- : memory cell
- : update gate
- : relevance gate
なお、 はアダマール積 (要素ごとの積) を示しており、 はすべて同じ次元です。
GRUはこの後紹介するLSTMをシンプルにしたモデルで、LSTMに比べると後発のモデルです。GRUは隠れ層の構造が2つのゲート構造でシンプルなので、より大きなモデルを学習したいときにはゲートが3つあるLSTMに比べると有利に働く場合があります。
Long Short Term Memory (LSTM)
LSTMはGRUに比べるとゲートの数が多く、すべてのパラメーターについてゲートがあります。また、LSTMではmemory cellを活性化関数と分けて個別に保持します。これによってLSTMはGRUに比べると過去の状態を保持しやすいです。

- : update gate
- : forget gate
- : output gate
より深くLSTMを理解したい方は下記のブログが参考になります。
Bidirectional RNN (BRNN)
これまで見てきたRNNは一方向の時間遷移に対してしか状態を渡しませんでしたが、BRNNでは両方向の時間遷移に対して情報を引き渡します。

もちろん入力としてすべての時刻の時系列データを必要とするため、音声認識システムなどで使う場合には、すべての時系列データの入力が終わるまで待たなければなりません。
Deep RNN (DRNN)
一般的なディープニューラルネットワークは50層や100層などの深さが一般的ですが、RNNの場合は3層でも十分大きいニューラルネットワークといえます。これは、RNNには時系列の次元があるためです。
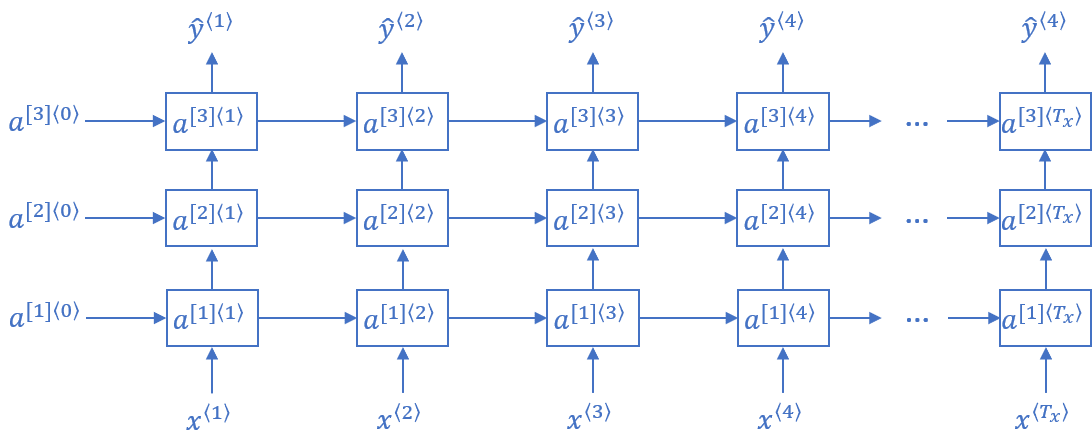
DRNNの後に時系列の結合がないディープニューラルネットワークを使う場合もあります。
今回は以上です。 最後まで読んでいただき、ありがとうございます。
CourseraのDeep Learning専門講座の他のコースの受講メモ
- コース1: Neural Networks and Deep Learning
- コース2: Improving Deep Neural networks
- コース3: Structuring Machine Learning Projectsについて
- コース4: Convolutional Neural Network
- コース5: Sequence Models
コメント
コメントを投稿