

Apache Airflow入門
この記事のまとめ:
- Apache Airflow初心者がAirflowのアーキテクチャを理解し、チュートリアルを動かすまでの手順をまとめています。
背景
cronの代わりにタスクの実行を行うタスクスケジューラーとして、なんかよくわからんけどAirflowを使わなければならない状況だったので、Airflowがどういうものなのかと、簡単な動作方法を調べてみましたので、それらをまとめています。
Airflowとは
Airflowがどんなものなのか、最初くらいは公式ドキュメントを読んでみようと思います。
Airflow is a platform to programmatically author, schedule and monitor workflows.
Use airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative.
日本語で要約すると次のような感じですかね。
- Airflowは、有向非巡回モデル (DAG) としてタスクのワークフローを作るためのものである
- Airflow schedulerがDAGに従ってタスクを実行する
- リッチなUIを通じて、パイプラインの表示、進捗のモニター、問題のトラブルシュートを簡単にしてくれる
その他、概要やメリットの説明は他の記事でもたくさんありますので、それらから要約すると、Airflowはcronでは手間のかかるワークフローとしてのタスクの実行、モニター、ロギングなんかができることがメリットのようです。
Airflowのアーキテクチャ
Airflowはシングルコンポーネントのシステムではないので、全体の理解のためにアーキテクチャを見てみます。
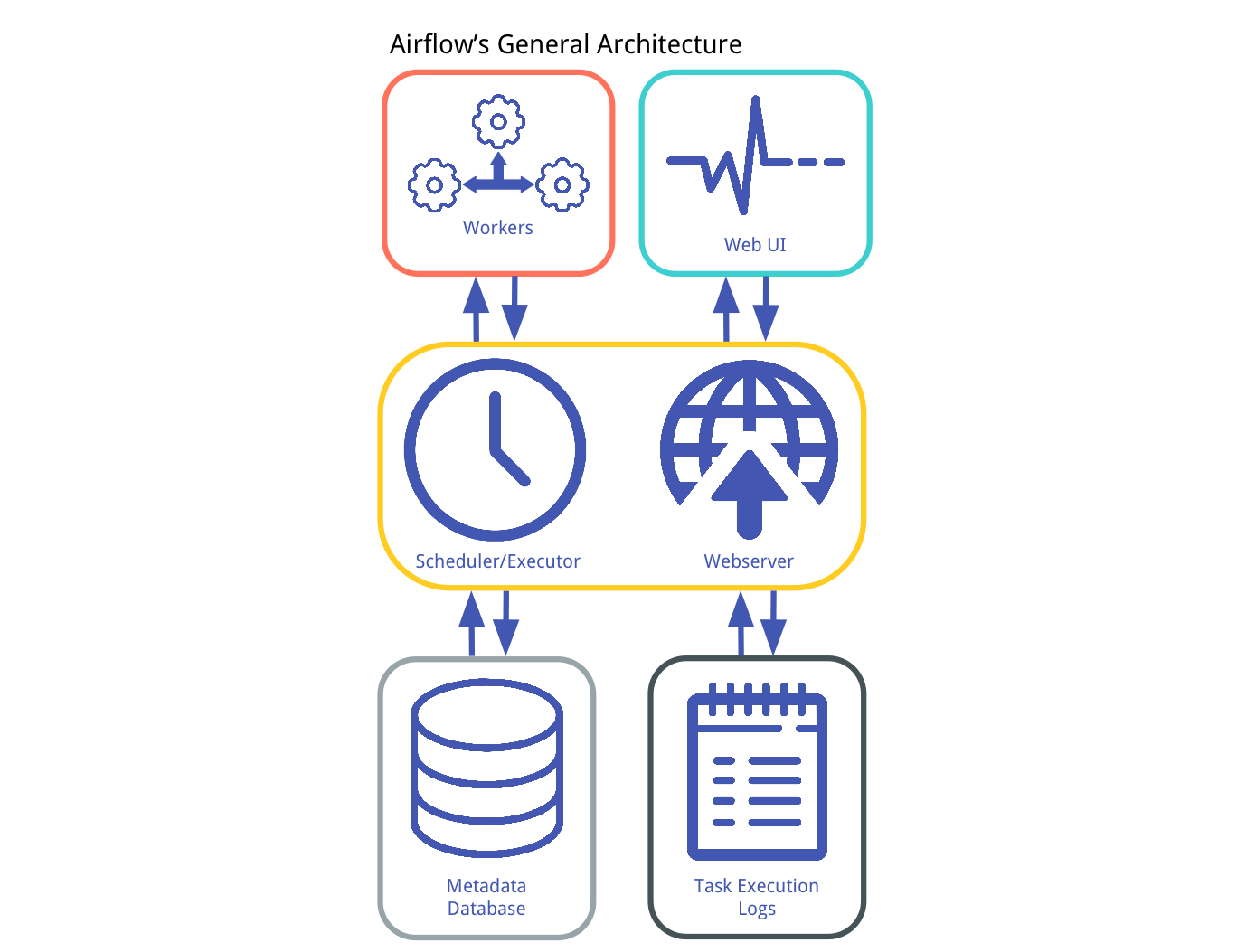
(参照元: Understanding of Apache Airflow’s Key Concepts)
- Metadata DB : タスクの状態に関する情報が保存されます。データベースの更新にはSQLAlchemyを使って実装されているため、SQLAlchemyがサポートしているデータベースであれば使えそうです。
- Scheduler : 実行するタスクを決定するプロセスです。決定にあたっては、DAGで定義されたタスクと、メタデータDB内のタスクの状態とを使い、どのタスクを実行すべきか、その優先度を決定します。
- Executor : メッセージのキューイングするプロセスです。ExecutorとSchedulerは密に結合しており、スケジュールされた各タスクを実際に実行するWorkerプロセスを決定します。次のような異なるタイプのExecutorがあります。
SequentialExecutor: Schedulerプロセスと同じマシン上でタスクをシーケンシャルに処理するLocalExecutor: Schedulerプロセスと同じマシン上でタスクを並列処理するCeleryExecutor: Workerマシンのクラスタにタスクを分散して並列処理する
- Workers : タスクのロジックを実際に実行するプロセスです。Executorによって決定されます。
- Webserver : 単純なFlaskのアプリケーションで、全タスクの状態をmetadata DBから読み出し、Web UIに表示します。
- Web UI : クライアントサイドのユーザーがmetadata DBの中のタスクの状態を見たり、schedulerの振る舞いを編集したりできるようにするコンポーネントです。
- Execution Logs : Workerプロセスの実行ログです。ディスクストレージかリモートファイルストレージ (e.g. GCSやS3)のどちらかに保存ができます。WebserverはこれらのログをWeb UIに表示できるようにします。
このようにAirflowには主に上記の7つのコンポーネントがあります。その中でもAirflowのプロセスとしては、Scheduler/Executor (ユーザーからは分かれて見えない)とWebserverの2つが重要なプロセスです。この2つを意識しながら次に動作を見ていきます。
Airflowのインストール
アーキテクチャの通り、Airflowのインストレーションは結構複雑なので、Dockerコンテナとしてある程度準備されているものを使う方が便利です。
ただし、残念ながら本記事執筆時点 (2019.03.11) では公式のDockerコンテナはないようですので、野良のDockerコンテナを探して使うしかありません。その中で、 puckel/docker-airflow はDockerHubでは最もpullの多いAirflowのDockerコンテナのようですが、元の Github を見るとすでにメンテナンスされていない感じもします。
ただし、このpuckel/docker-airflowからフォークされている zhongjiajie/docker-airflow は本記事執筆時点では比較的メンテナンスされているようなので、こういったものを見つけて使う、もしくは更にフォークさせて最新対応させるなどするとよいと思います。
Airflowの実行
それでは、zhongjiajie/docker-airflow をもとに簡単に使い方を見ていきます。なおここでは、簡単なところから理解するために LocalExecutor を使ってみようと思います。
早速実行してみます。
docker-compose-LocalExecutor.yml に書かれた通り、PostgreSQLとWebserverのコンテナが立ち上がります。Webserverといっても、script/entrypoint.sh の75行目、77行目の通り、コンテナの中にSchedulerとWebserverの両方のプロセスが動いています。
そして、ありがたいことにあらかじめチュートリアルのDAGも dags/tuto.py に用意されてあり、yamlファイルの19行目の通り、コンテナ起動時にこのDAGが読み込まれるように設定されています。この tuto.py は公式ドキュメントに記載されているチュートリアルそのものです。その詳細はドキュメントを読めば何をやろうとしているかわかりますが、簡単に、Web UIを見ながら中身を見てみます。
まずは localhost:8080 をブラウザで開きます。
Scheduleの列をみると、”1 day, 0:00:00” となっており、0:00:00に1日おきに実行するという意味で、これは13行目で定義している "start_date" や25行目の schedule_interval=timedelta(days=1) となっているところからきています。
さらに、Linksの中から左から2つ目のアイコンを押して、Tree Viewを見てみます。
タスクのワークフローはこのように定義されており、dags/tuto.py と見比べてみるとどのように構成されるかよくわかると思います。また、”sleep” → “print_data” と “templated” → “print_date” とつながっていることがわかります。これは依存関係を示しており、dags/tuto.py の47、48行目で定義されていることが反映されています。
大体の構成が見えてきたかと思いますので、一度DAGをマニュアルで実行してみます。ホームに戻ってLinksの一番左に “Trigger DAG” というアイコンを押すとマニュアルで実行ができます。
※なお、初期のAirflowのコンフィグでは過去にさかのぼってキューを実行するモードになっているので、dags/tuto.py の "start_date" がかなり古いと数百、数千というタスクがキューにたまるので実行する前に "start_date" は変更した方が無難です。
しばらくして画面を更新すると、DAG Runsの列に “success” の円が出てき、ワークフローが実行できたということ確認できます。
もう少し詳細を見るために実行ログを見ていきます。Tree Viewを表示すると過去の実行結果がタスクごとに確認できます。
今回は、タスクの定義も理解するために、”templated” タスクのうちで “success” になっているものを表示します。
右上の “View Log” を押します。そうするとログが表示されます。 ※なお、この画面に遷移する方法はこのひとつだけではありませんので、いろいろ試してみてください。
ほとんどはAirflowが作成するログですが、赤枠で括弧った部分が実行したコマンドによる標準出力への結果です。なぜ、このような出力がされているかについて少し見てみます。
ここで改めて、dags/tuto.py に記述されている ”templated” のタスクを見てみます。
{{}}で囲われているものはすべてAirflow独自のマクロです。公式ドキュメントを見ると詳細はわかりますが、上から次のようなマクロです。
{{ ds }}: the execution date asYYYY-MM-DD{{ macros.ds_add(ds, 7) }}: Add or subtract days from a YYYY-MM-DD{{ params.my_param }}: a reference to the user-defined params dictionary which can be overridden by the dictionary passed throughtrigger_dag -cif you enableddag_run_conf_overrides_paramsin ``airflow.cfg`
これらを踏まえると赤枠で囲われたログが出力されたことが理解できます。
ひとまず、このくらいでAirflowの全体的な動きがわかったので、あとは自分の思い通りにDAGを編集すればとりあえず動きそうです。
適宜動かしてみてまた困ったら記事にまとめるかもしれません。
今回は以上です。 最後まで読んでいただき、ありがとうございます。
コメント
コメントを投稿